Gemma 4 acelerado por NVIDIA RTX
Com o lançamento da família Gemma 4 de modelos de IA do Google, os entusiastas da IA agora têm acesso a uma nova classe de IA pequena, rápida e omni-capaz, projetada para implantação local rápida e eficiente, e as GPUs NVIDIA RTX podem acelerá-las com grande efeito. O Google e a NVIDIA trabalharam em estreita colaboração para otimizar os modelos Gemma 4 para PCs e estações de trabalho com tecnologia NVIDIA RTX, como o supercomputador pessoal de IA NVIDIA DGX Spark e o NVIDIA Jetson Orin Nano.
Seus incríveis recursos de IA local o tornam ideal para execução em um PC RTX equipado com gráficos NVIDIA GeForce RTX. GPUs de primeira linha, como NVIDIA GeForce RTX 5090 para consumidores, NVIDIA RTX 5000 para profissionais e NVIDIA DGX Spark para os entusiastas e desenvolvedores mais sérios de IA, oferecem hardware de alta velocidade dedicado à IA para executar esses modelos de ponta e Tensor Cores com desempenho aprimorado para executá-los em velocidade máxima para respostas de latência mais baixa.
Os modelos Gemma 4 são executados em llama.cpp e Ollama com otimizações RTX, permitindo desempenho de IA local rápido e responsivo.
PCs RTX permitem inferência mais rápida no Gemma 4
Os modelos Gemma 4 do Google são projetados para oferecer um raciocínio sólido na resolução de problemas, geração de código rápida e eficiente e recursos de depuração, suporte para uso de ferramentas de agente e recursos avançados de vídeo e áudio. Eles também oferecem suporte multilíngue para que possam ser usados por qualquer pessoa em todo o mundo.
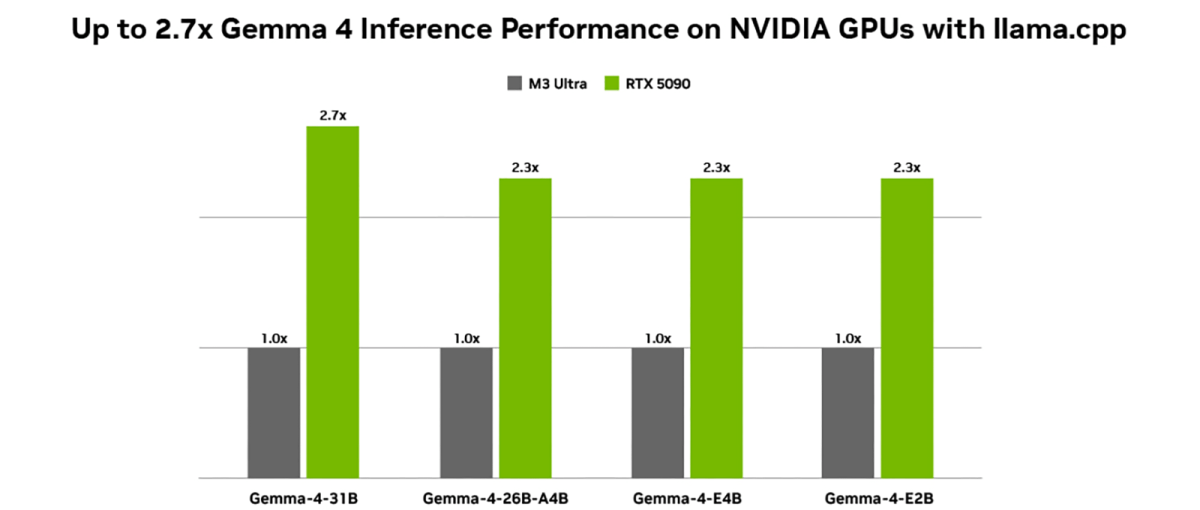
Mas você só obtém todos os recursos dos modelos Gemma 4 ao executá-los em GPUs NVIDIA RTX. Ao executar o Gemma 4-31B em um NVIDIA RTX 5090, você pode desbloquear quase três vezes o desempenho em comparação com alternativas poderosas, como o MacBook M3 Ultra. Modelos menores também foram igualmente melhorados, com Gemma 4-26B-A4B e Gemma 4-E4B também mostrando mais de duas vezes melhorias de desempenho ao migrar para um RTX 5090.
NVIDIA
Totalmente compatíveis com OpenClaw, os modelos Gemma 4 permitem que os usuários criem agentes locais rápidos e capazes que aproveitam arquivos locais para atender às solicitações do usuário em aplicativos locais e cargas de trabalho automatizadas. Ao executar em hardware gráfico NVIDIA RTX, você pode ter certeza de que esses agentes estão trabalhando com desempenho e eficiência máximos.
Ajuste fino acelerado
Um ponto forte da execução de modelos locais de IA em seu próprio hardware é o ajuste fino acelerado. O ajuste fino permite treinar novamente um modelo com seus próprios dados, extraindo-o de uma poderosa ferramenta de uso geral e transformando-o em um dispositivo personalizado para seus fluxos de trabalho específicos. Isso permite melhorar a qualidade da resposta e ajudar a adaptar os resultados às necessidades do seu negócio.
A NVIDIA oferece o melhor suporte da categoria para esse processo por meio de ferramentas populares, todas desenvolvidas com base no PyTorch e otimizadas para GPUs NVIDIA RTX. Com os modelos Gemma 4, você obtém a IA local mais avançada para X e Y, mas com o ajuste fino suportado pela NVIDIA, você pode personalizá-la exatamente de acordo com seus casos de uso.
Pronto desde o dia 0
Os desenvolvimentos de IA estão ocorrendo em grande escala e pode ser difícil acompanhar o que está por vir e o que já foi lançado. Uma das melhores maneiras de garantir que você esteja sempre pronto para aproveitar as vantagens do desenvolvimento mais recente em modelos locais de IA é ter uma GPU NVIDIA RTX em mãos e pronta para uso.
As placas gráficas da série RTX 50 da NVIDIA têm VRAM suficiente para carregar os modelos Gemma 4 e vários outros. Seus Tensor Cores ajudam a acelerar as cargas de trabalho de IA para treinamento e inferência mais rápidos, e os kits de ferramentas compatíveis com CUDA oferecem controle total para selecionar modelos, alternar quantizações, ajustar parâmetros ou executar seus próprios fluxos de trabalho.
Com a IA local em execução em um PC RTX, você obtém suporte para os modelos e recursos de IA mais avançados, ajudando você a aproveitar as vantagens da IA mais recente de hoje e a se preparar para o que está por vir.
Desempenho de memória aprimorado com GPUs RTX
Um dos principais componentes no desenvolvimento dos modelos locais de IA mais eficazes, como as variantes Gemma 4, é otimizar a eficiência da memória. Onde os data centers de computação em nuvem podem aumentar continuamente o tamanho do modelo, os modelos locais de IA precisam ser mais eficientes. É por isso que a NVIDIA está no centro da otimização de memória de modelos locais de IA há anos.
A NVIDIA foi pioneira na aceleração exclusiva RTX do NVFP4 – um formato de ponto flutuante que reduz o consumo de VRAM em até 60% em GPUs NVIDIA baseadas na arquitetura Blackwell. Quando alimentada pelos Tensor Cores de quinta geração da NVIDIA, a aceleração de IA atinge novos picos de desempenho. As GPUs mais recentes podem gerenciar trabalhos em uma fração do tempo até mesmo em alternativas de alta potência, como os MacBooks de nova geração da Apple.
Por que o RTX é melhor para IA local
Embora os modelos de IA mais capazes provavelmente sempre precisem contar com o poder da computação em nuvem escalável, existem pontos fortes incríveis na execução da IA localmente que não podem ser ignorados.
Onde a privacidade dos dados é de suma importância, executar a IA localmente garante que os dados nunca saiam do seu sistema, mantendo as informações confidenciais inteiramente sob seu controle. Para organizações e indivíduos que lidam com dados confidenciais, usar uma solução local de IA executada em uma placa gráfica NVIDIA RTX GeForce é a melhor maneira de protegê-los. Isso é duplamente importante se você estiver aproveitando a IA agente para executar tarefas no seu PC para você.
Quando você executa um modelo de IA localmente, é mais fácil fornecer todos os dados de contexto necessários. Em vez de enviar terabytes de informações para a nuvem, onde surgem preocupações com a privacidade e a interferência na rede pode desperdiçar horas, a IA local tem tudo o que precisa naquele momento e o ajuste fino de acompanhamento também é mais fácil e eficiente.
Mesmo sendo uma ferramenta transformacional no local de trabalho, os custos relacionados à IA ainda precisam ser rastreados e medidos: os tokens precisam levar ao aumento da produtividade e da lucratividade. Contar com IA executada localmente em seu próprio hardware RTX garante que você possa gerenciar os custos em cada etapa do processo, desde a compra inicial até a implantação e manutenção contínua. Não há necessidade de assinaturas de IA na nuvem ou taxas de token de longo prazo. Basta fornecer a energia e sua poderosa placa gráfica NVIDIA GeForce RTX AI cuidará do resto.
A NVIDIA também oferece uma ampla gama de placas gráficas da série RTX 50 com capacidade de IA. Todas as placas gráficas Blackwell são construídas com Tensor Cores de aceleração de IA de última geração para recursos avançados de IA. Juntamente com placas principais como a RTX 5090 e sua contraparte profissional, a RTX PRO 6000, a RTX 5080 também é uma placa poderosa para desenvolvimento e ajuste de IA local.