Desenvolvedores e criativos que buscam maior controle e privacidade com sua IA estão cada vez mais recorrendo a modelos executados localmente, como a nova família de modelos gpt-oss da OpenAI, que são leves e incrivelmente funcionais no hardware do usuário final. Na verdade, você pode executá-lo em GPUs de consumo com apenas 16 GB de memória. Isso torna possível usar uma ampla variedade de hardware – com as GPUs NVIDIA emergindo como a melhor maneira de executar esses tipos de modelos de peso aberto.
Enquanto nações e empresas correm para desenvolver suas próprias soluções de IA sob medida para uma série de tarefas, modelos de código aberto e de peso aberto, como o novo gpt-oss-20b da OpenAI, estão encontrando muito mais adoção. Este último lançamento é aproximadamente comparável ao mini modelo GPT-4o, que teve tanto sucesso no ano passado. Ele também introduz raciocínio em cadeia de pensamento para refletir profundamente sobre os problemas, níveis de raciocínio ajustáveis para ajustar as capacidades de pensamento em tempo real, extensão de contexto expandida e ajustes de eficiência para ajudá-lo a funcionar em hardware local, como as GPUs GeForce RTX série 50 da NVIDIA.
Mas você precisará da placa gráfica certa se quiser obter o melhor desempenho. A GeForce RTX 5090 da NVIDIA é sua principal placa super rápida para jogos e uma variedade de cargas de trabalho profissionais. Com sua arquitetura Blackwell, dezenas de milhares de núcleos CUDA e 32 GB de memória, é ideal para executar IA local.
Llama.cpp é uma estrutura de código aberto que permite executar LLMs (modelos de linguagem grande) com ótimo desempenho, especialmente em GPUs RTX, graças às otimizações feitas em colaboração com a NVIDIA. Llama.cpp oferece muita flexibilidade para ajustar técnicas de quantização e descarregamento de CPU.
Llama.cpp publicou seus próprios testes de gpt-oss-20b, onde a GeForce RTX 5090 liderou as paradas com impressionantes 282 tok/s. Isso é comparado ao Mac M3 Ultra (116 tok/s) e ao 7900 XTX da AMD (102 tok/s). A GeForce RTX 5090 inclui Tensor Cores integrados projetados para acelerar tarefas de IA, maximizando o desempenho executando gpt-oss-20b localmente.
Observação: Tok/s, ou tokens por segundo, mede tokens, um pedaço de texto que o modelo lê ou gera em uma única etapa, e a rapidez com que eles podem ser processados.

NVIDIA
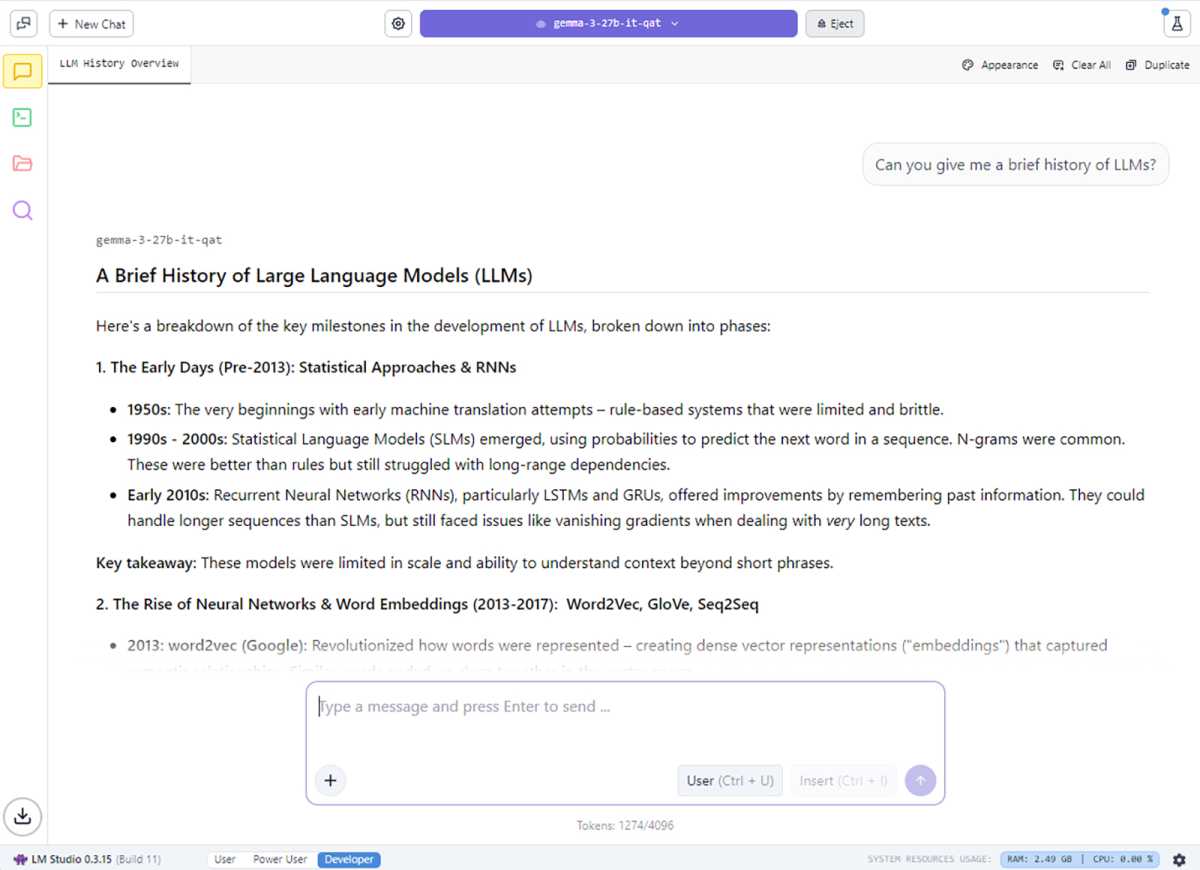
Para entusiastas de IA que desejam apenas usar LLMs locais com essas otimizações NVIDIA, considere o aplicativo LM Studio, desenvolvido com base em Llama.cpp. O LM Studio adiciona suporte para RAG (geração aumentada de recuperação) e foi projetado para facilitar a execução e a experimentação de grandes LLMs, sem a necessidade de lidar com ferramentas de linha de comando ou configurações técnicas profundas.
NVIDIA
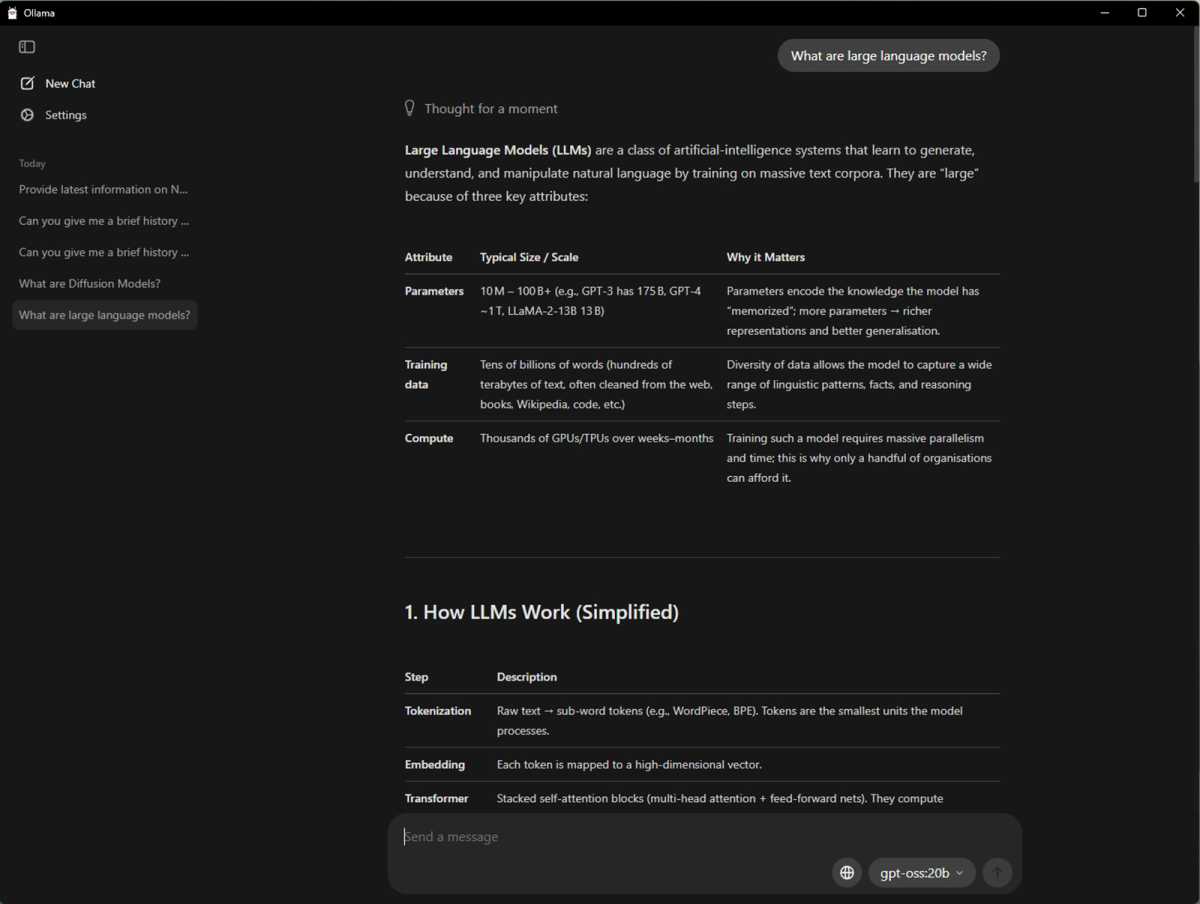
Outra estrutura de código aberto popular para testes e experimentação de IA é o Ollama. É ótimo para testar diferentes modelos de IA, incluindo os modelos OpenAI gpt-oss, e a NVIDIA trabalhou em estreita colaboração para otimizar o desempenho, para que você obtenha ótimos resultados executando-o em uma GPU NVIDIA GeForce RTX série 50. Ele gerencia downloads de modelos, configuração de ambiente e aceleração de GPU automaticamente, bem como gerenciamento de modelos integrado para suportar vários modelos simultaneamente, integrando-se facilmente com aplicativos e fluxos de trabalho locais.
Ollama também oferece uma maneira fácil para os usuários finais testarem o modelo gpt-oss mais recente. E de forma semelhante ao llama.cpp, outros aplicativos também utilizam o Ollama para executar LLMs. Um exemplo é AnythingLLM, com sua interface local simples, tornando-o excelente para aqueles que estão apenas começando com o benchmarking LLM.
NVIDIA
Se você possui uma das GPUs NVIDIA mais recentes (ou mesmo se não tiver, mas não se importe com o impacto no desempenho), você pode experimentar o gpt-oss-20b em uma variedade de plataformas. O LM Studio é ótimo se você deseja uma interface elegante e intuitiva que permite pegar qualquer modelo que você deseja experimentar e funciona igualmente bem no Windows, macOS e Linux.
AnythingLLM é outra opção fácil de usar para executar gpt-oss-20b e funciona tanto no Windows x64 quanto no Windows em ARM. Há também o Ollama, que não é tão elegante de se ver, mas é ótimo se você sabe o que está fazendo e deseja configurar rapidamente.
Qualquer que seja o aplicativo que você use para brincar com o gpt-oss-20b, as GPUs NVIDIA Blackwell mais recentes parecem oferecer o melhor desempenho.